Azure ML Studio 밋업 세미나
데브옵스 코리아 대표 조철현
전미정 강사
앱 개발 Keras
인공지능 전문가만 하는 것은 아니다.
1부. 머신러닝 개론
2부. 핸즈옵 랩
기계를 인간과 비슷하게 동작하게 만드는 기술
인지 이해 반응
인공지능 -> 머신러닝 -> 딥러닝(머신러닝을 구헌하는 다양한 방법 중에 하나)
데이터가 있어야 머신러닝을 할 수 있다.
Machine Learning Bubble Chart
Supervised Learning(지도 학습, 감독학습)
문제와 정답 제공
-Feature & Label
예측, 추정, 분류
-Regression/Forecast/Classification
(쉽고 성능도 잘 나오는 편이다.)
시간에 따른 커피의 소비량(회귀)
Unsupervised Learning(비지도 학습)
문제만 제공
-Feature
패턴/구조 발견
그룹화
Anomaly Detection 비정상거래를 감지
Clustering
태깅을 하지 않고도 작업할 수 있다.
Reinforcement Learning(강화 학습)
보상 제공
인과관계가 중요
게임(알파고), 로봇
머신러닝 방법
방법이 엄청나게 많다. ML Studio에서 제공되는 것은 무엇인지 본다.
뉴럴 네트워크가 바로 딥러닝이다. 인간이 학습하는 뇌구조처럼 컴퓨터도 비슷하게 처리해 보자.
입력
입력 인공신경 출력
입력
층을 여러개 쌓아서 처리할 수 있다.
머신러닝 딥러닝
Input Input
Feature Engineering Feature Extraction
Traditional ML Neural Network
Output Output
(도메인에 대한
전문적인 지식이 필요하다.)
(피처가 많다면... 피처의 추출을 기계가 한다. )
머신러닝의 헬로우월드 타이타닉 생존여부
Y = w*X + b
(라벨). (피처)
근무 연수 연봉
....
데이터에 점을 찍을 수 있다.
실제 값을 통해 데이터 값을 구할 수 있다.
w와 b를 머신러닝 모델이 구해줍니다.
X = Feature Y = Label
70~80%는 학습에
사용한다.
30%는 테스트에 사용
슈퍼바이저의 리그레션을 하게 됨
친절한 Azure ML Studio HOL
custom model 생성
전통적인 머신러닝 방법을 사용한다.
microsoft model 활용
Cognitive Service를 통해 미리 만들어진 것을 쓴다.
Azure Machine Learning Studio
Azure Machine Learning Service
하이퍼 파라메터들의 값
파이썬을 잘하고 싶은 것이 아닌 머신러닝을 하고 싶은데...
추가로 코드를 연결할 수 도 있다.
Best tool for ML Beginner
무료도 가능 10기가 까지 데이터 가능
문제 정의
데이터 셋 준비
모델 설정
모델 훈련 / 평가
모델 활용
총 111개 모듈
미국 45개 월 마트 부서별 주간 판매액 예측 모델
part1. 데이터 전처리
part2. 모델 학습 / 예측
part1. 데이터 전처리
데이터 지원 형식
원만한 데이터는 다 지원이 된다.
데이터 지원 유형
문자열
정수
double
BOOLEAN
Datetime
timespan
데이터 지원 용량
2기가
전체 10기가 정도(무료 버전)
kaggle에 올라왔던 문제임
feature.csv. train.csv. stores.csv
12열 8천개 5열 42만개. 3열 45개 지점
3개를 키를 통해 스튜디오에서 묶어서 사용한다.
키는 지점을 잡으면 된다. 그리고 날짜로 묶는다.
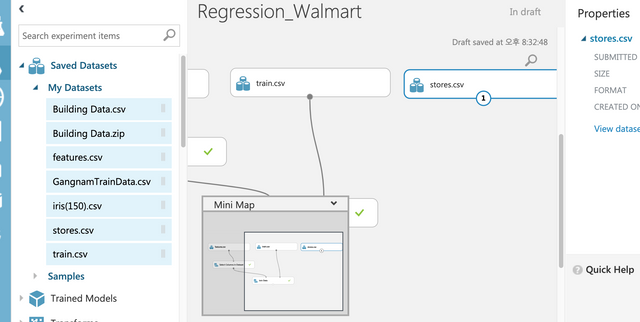
3개의 파일을 모두 업로드를 한다.
왼쪽의 데이터셋 아이콘을 클릭하고 From Local File이 나오면 3개의 파일을 모두 업로드하면 된다.
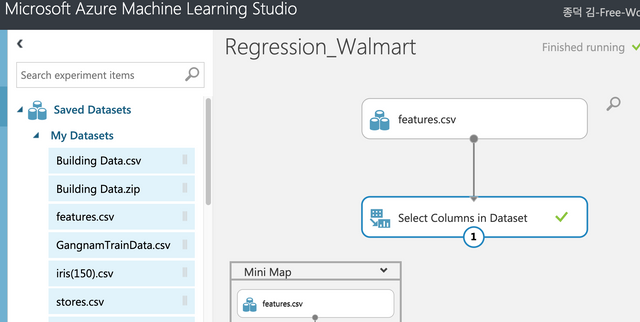
Saved Datasets에서 My Datasets를 클릭해서 업로드한 파일중에 features.csv파일을 드래그&드롭한다.
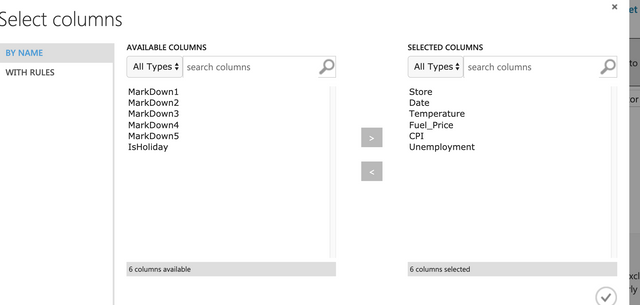
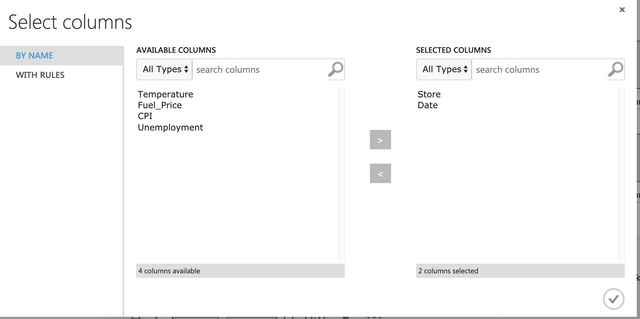
Features에서 6개의 컬럼만 선택한다. 마크다운, 홀리데이는 제외한다. Select Columns in Dataset에서 아래와 같이 선택하면 된다.
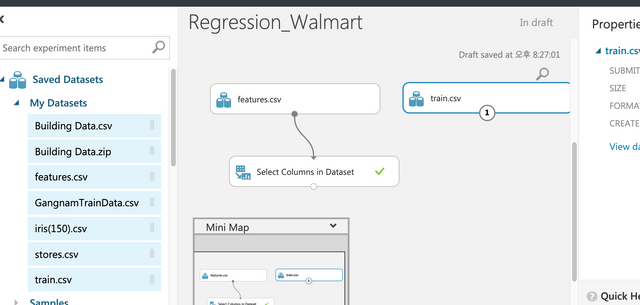
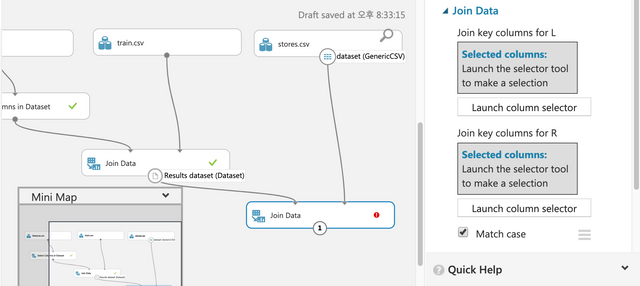
이번에는 업로드한 파일 중에 train.csv파일을 드래그&드롭한다. 데이터를 키컬럼을 사용해서 조인해야 한다.
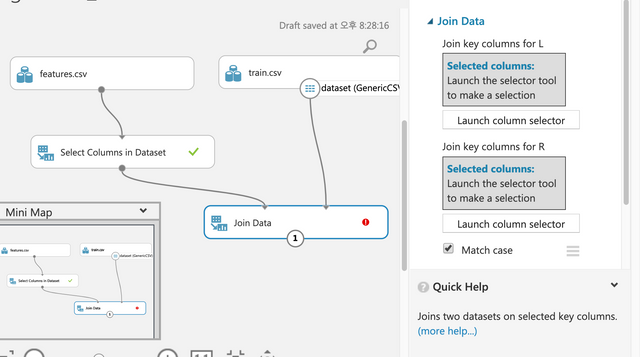
Join Data를 드래그&드롭하고 라인을 아래와 같이 연결한다.
Match Case의 경우 대소문자 구문 지금은 동일하다. 체크한 상태
Keep right key는 언체크해서 동일한 컬럼이 생기지 않게 한다. 양쪽 데이터셋에 같은 컬럼이 있기 때문에 중복이 발생하지 않도록 언체크해야 한다.
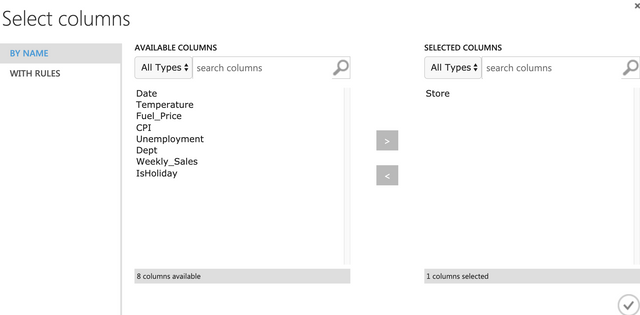
이번에는 stores.csv파일을 드래그&드롭하고 join data를 드래그&드롭해서 아래와 같이 연결한다.
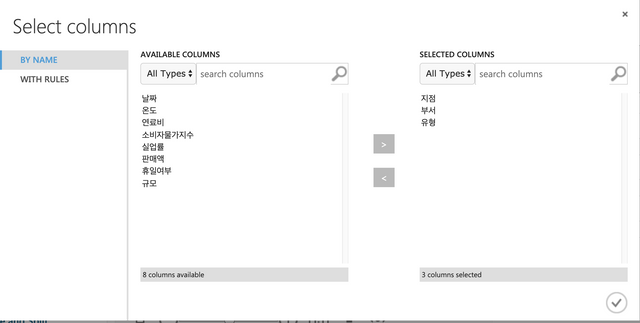
이번에는 Store만을 선택해서 키로 추가해서 조인을 처리하면 된다.
하단의 Run버튼을 클릭해서 실행결과를 한번 확인해 본다.
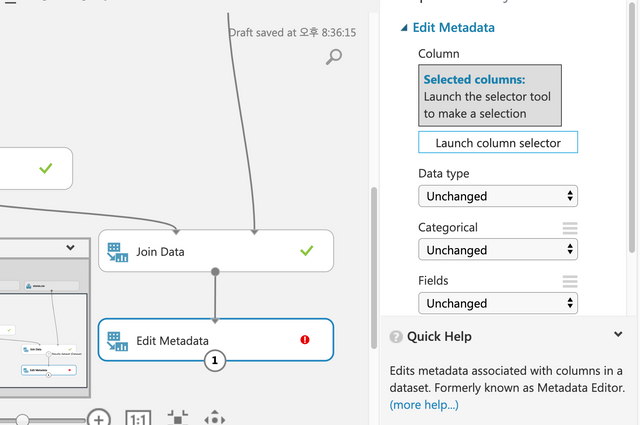
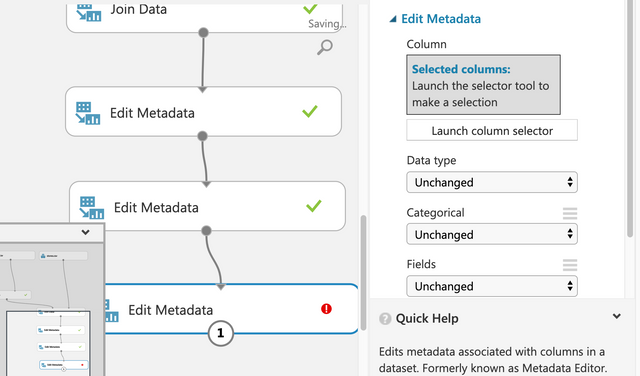
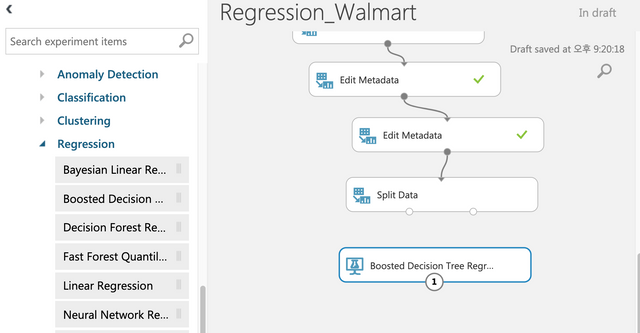
Edit Metadata를 사용해서 데이터를 전처리 한다.
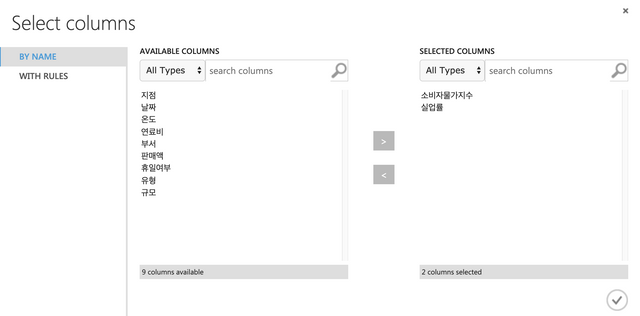
오른쪽 상단의 Launch column selector에서 11개의 컬럼을 모두 선택해서 오른쪽으로 배치한다.
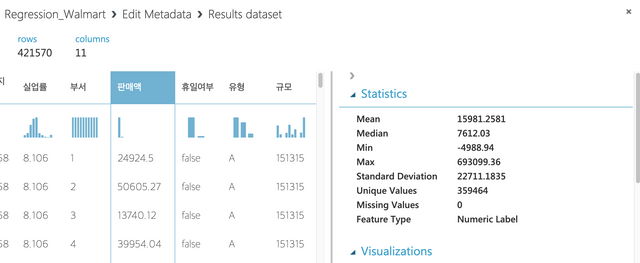
New column names에 아래와 같이 한글로 된 컬럼이름을 입력한다. 갯수가 11개인지 체크한다.
지점,날짜,온도,연료비,소비자물가지수,실업률,부서,판매액,휴일여부,유형,규모
Edit Metadata를 하나 더 드래그&드롭한다. 위에서 아래로 라인을 연결한다. 추가된 Edit Metadata에서 Launch Select Column을 클릭한다.
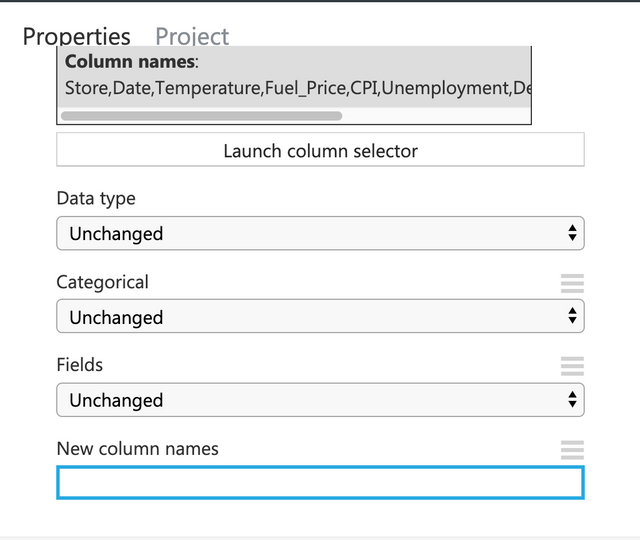
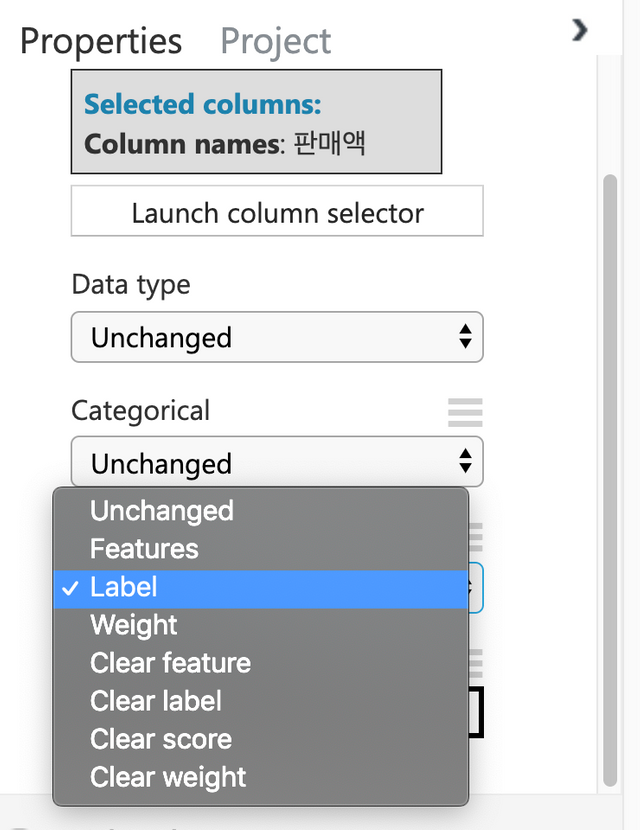
카테고리형태로 입력되는 3개의 피처들이 있다. 지점,부서,유형을 선택해서 카테고리형태로 변경해 주도록 한다.
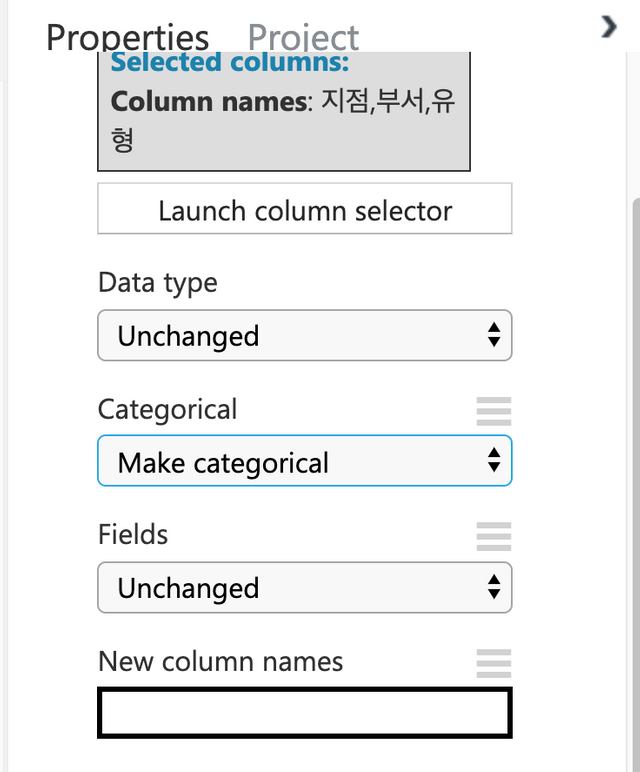
오른쪽의 Properties에서 Categorical을 Make categorical로 변경한다.
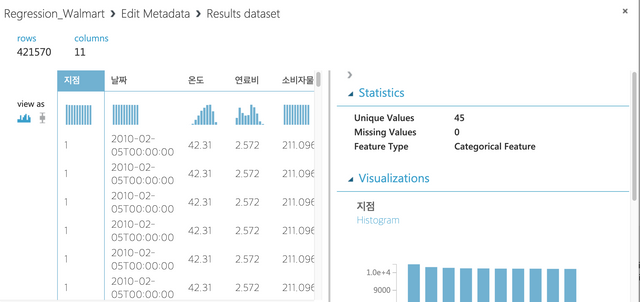
Run을 하고 결과를 보면 아래와 같이 Statistics에 Feature Type이 Categorical Feature로 변경되어 있다.
다시 Edit Metadata를 하나 더 추가한다. 아래와 같이 연결한다
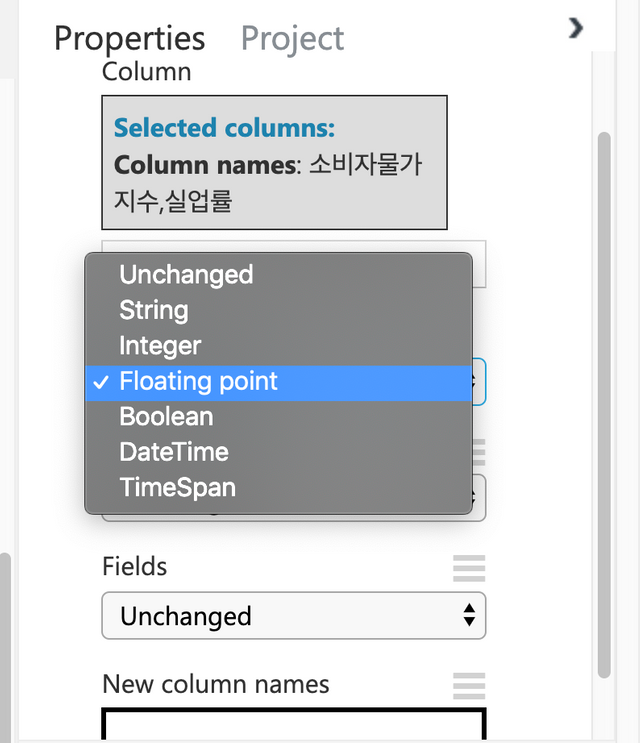
소비자물가지수와 실업률을 선택한다.
Feature가 String으로 되어 있는 것을 아래와 같이 Data Type에서 Floating point로 변경한다.
다시 하나 더 Edit Metadata를 추가한다.
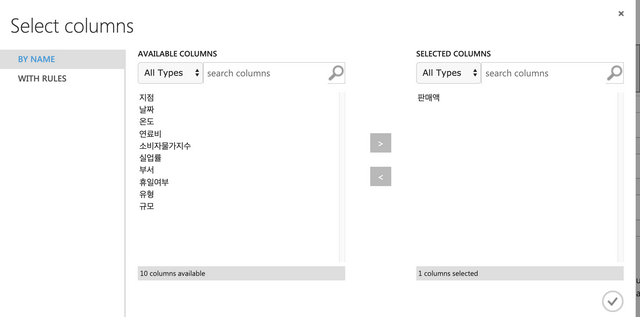
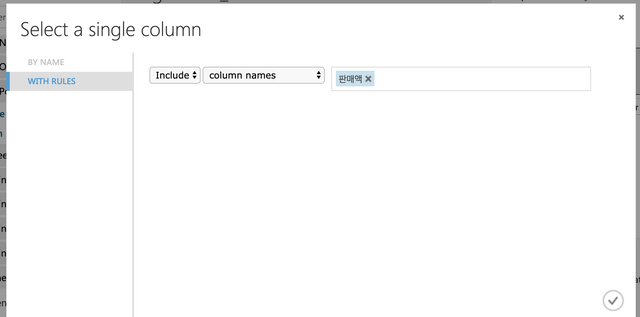
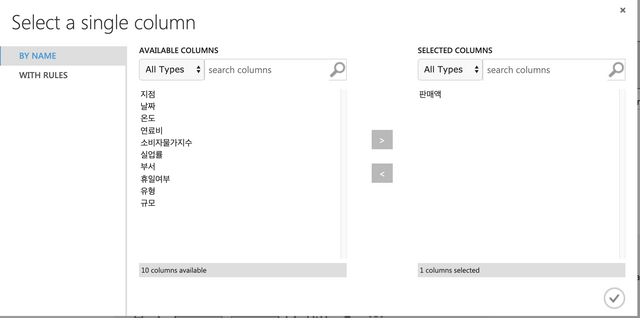
판매액을 선택한다.
아래와 같이 Fields에서 Label로 변경한다.
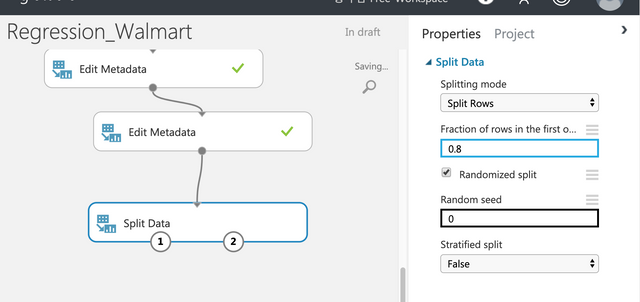
트레이닝과 테스트를 분리하기 위해 아래와 같이 Split Data를 연결한다. 0.8을 입력한다.
Random seed에는 0이 아는 좋아하는 아무 숫자나 입력하면 된다. 99를 입력한다. 앞에서부터 추출하는 것이 아는 랜덤하게 추출해서 훈련과 테스트가 정상적으로 진행될 수 있다.
Random Split
데이터가 순서대로 나열되어 있을 수 도 있기 때문에 랜덤하게 데이터를 뽑아와야 한다.
0.8을 입력해서 80프로 / 30프로로 나누어서 사용한다.
Random seed를 준다. 약간의 성능차이가 날 수 있다. 성능의 차이가 알고리즘인지? 랜덤해서 만든건지? 랜덤시드를 고정하면 이럼 고민을 덜 수 있다. 랜덤 선별 방식을 고정할 수 있다. 랜덤하게 뽑는 규칙은 고정하겠다는 것이 랜덤시드이다.
랜덤시드를 0으로 하면 사용하지 않겠다는 뜻. 원하는 숫자를 아무거나 입력한다.
Stratified Split
샘플링을 해야 한다.
데이터를 가지고 생각할 것이 엄청나게 많다.
케라스 코리아 You Only Look Keras
Initial Model 알고리즘 선택
Train Model 모델을 트레이닝
Score Model 평가하는 모델
Evaluate Model
Deploy Model
어떤 알고리즘을 써야하는가? 그때 그때 마다 다르다.
On size & quality of data
지도 학습 - Classification, Regression, Anomaly Detection
비지도 학습 - 클러스터링
Reinforcement - 아직 지원 안함
Accuracy(정확도를 얼마만큼 할 것 인가?)
정확도를 너무 높이면 오버피팅이 발생하고 시간이 많이 걸린다.
Parameter
Feature
ML Studio는 25개의 알고리즘을 제공한다.
치팅 시트를 제공한다.
Regression에서 8개의 알고리즘을 제공한다.
Ordinal Regression ; 데이터 내 상대적 순서나 랭킹 예측
Poisson Regression : 이떤 이벤트가 발생할 횟수 예측. 어떤 사람이 병원에 가게될 횟수
Fast Forest Quantile Regression: 값의 분산/분포 예측
Linear : 선형 알고리즘
Bayesian Linear Regression
Neural Network Regression
Decision Forest Regression: 오퍼피팅에 중의
Boosted Decision Tree Regression: 이전 트리에 종속되어 있어 메모리 사용이 큼. 정확도가 높음. 앙상블 모델에 활용
(아래의 5개를 사용하면 된다.)
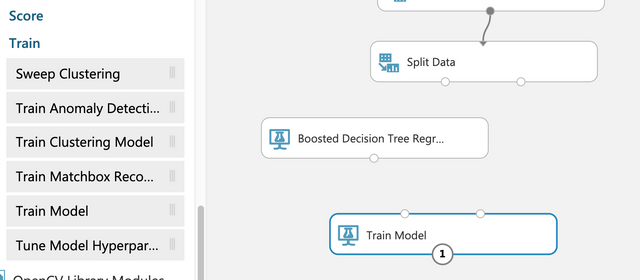
Boosted Decision Tree 를 알고리즘으로 사용한다.
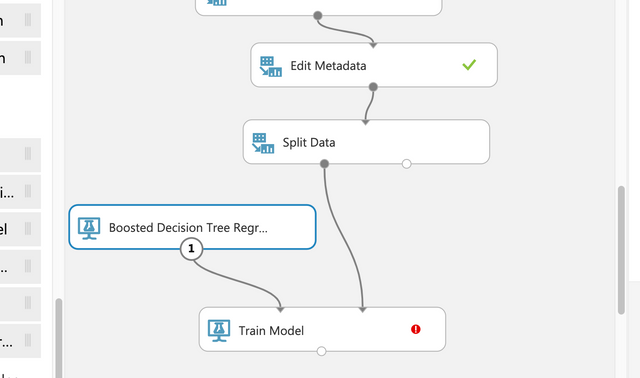
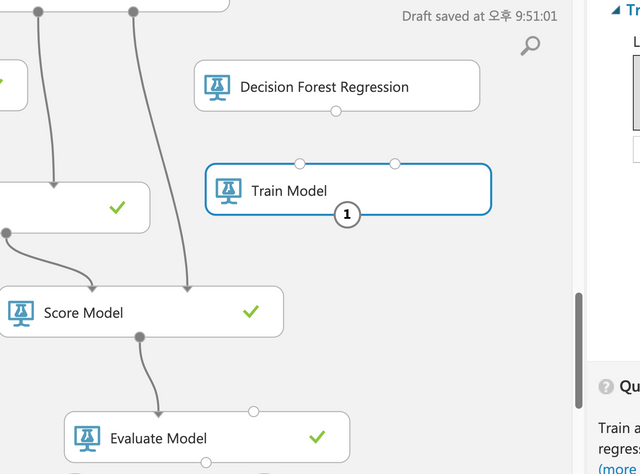
Boosted Decision Tree Regression과 Train Model을 연결하고 Split Data와 Train Model을 연결한다.
하단의 Run버튼을 클릭한다. 아래와 같은 Decision Tree가 나온 것을 볼 수 있다.
Score Model을 드래그&드롭하고 Train Model과 Score Model을 연결하고 Split Data에서 Score Model로 연결한다.
Evaluate Model을 드래그&드롭해서 아래와 같이 연결한다.
42만개의 데이터를 80프로는 모델, 20프로는 테스트로 사용한다.
판매액과 Scored Labels을 비교하면 잘 예측을 했는지를 알 수 있다. 우리가 예측한 모델이다.
Metrics가 5개로 나온다.
Mean Absolute Error 는 적은 값이 나오면 좋다.
p = predicted value 예측 값
a = actual value 실제 값
아래와 같이 시각화해서 결과를 확인할 수 있다.
Index Error. Error. Error^2
1 2 2 4
2 2 2 4
3 2 2 4
4 2 2 4
5 2 2 4
MAE(Mean Absolute Error)
MSE(Mean Square Error)
몇개의 튀는 데이터가 있다. 튀는 데이터를 중요하게 봐야 한다. 예측할 때 잘 맞추어야 한다.
골고루 맞추는 경우는 Mean Absolute Error를 사용한다.
모델이 잘 만들어진 것을 판단할 때 사용한다.
어떤 모델이 적합한지를 결정하기 힘들다. Evaluate Model의 상단에는 점이 2개가 있다. 동시에 2개를 연결할 수 있다.
All models are wrong
but some are useful
George Box
알고리즘이 맞을 것이라고 생각하지만 현실 세계를 다 맞추지는 못한다.
우리 데이터랑 잘 맞으면 쓸모가 있다. 여러개를 비교해 본다.
다른 알고리즘을 사용해서 성능을 비교해 볼 수 있다. 아래와 같이 똑같은 모델을 한번 더 생성한다.
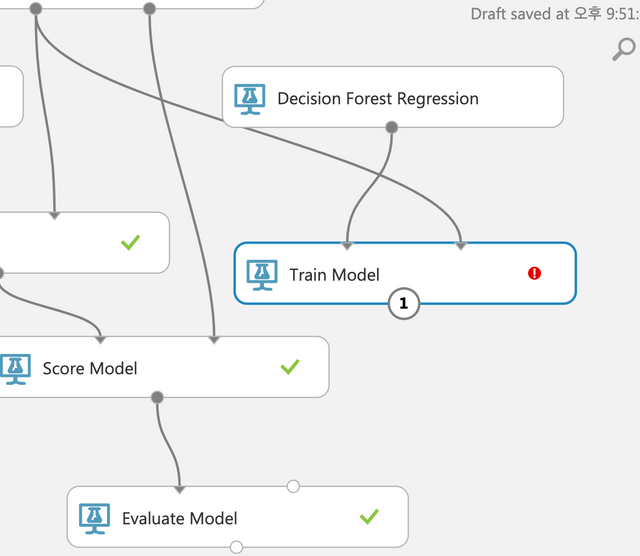
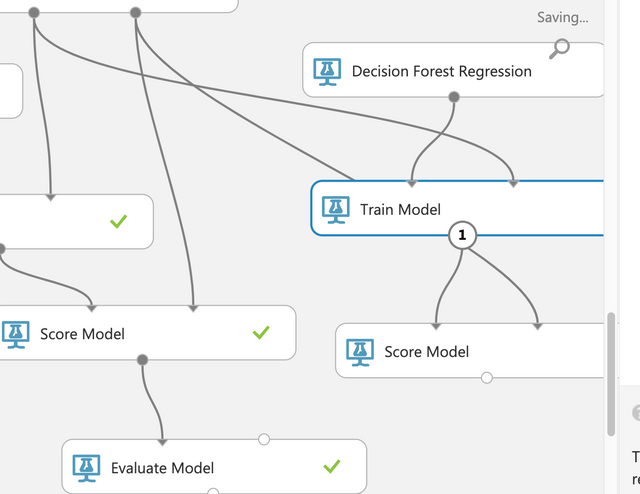
이번에는 Decision Forest Regression을 사용해서 Train Model과 연결한다.
Train Model에서 판매액을 선택한다.
Score Model을 추가해서 아래와 같이 Train Model과 Score Model을 먼저 첫번째 점과 연결한다. Split Data와 두번째 Score Model의 두번째 점으로 연결한다. 두번째 Score Model과 하단의 Evaluate Model을 연결해서 어떤 알고리즘이 더 유리한지 테스트할 수 있다. Run을 누르면 실행시간이 꽤 걸린다. 약 2분에서 5분정도 소요된다.
알고리즘 2개 중에 하나만 남겨둔다. 성능이 좋은 것은 남긴다. 왼쪽을 선택하고 오른쪽은 삭제한다.
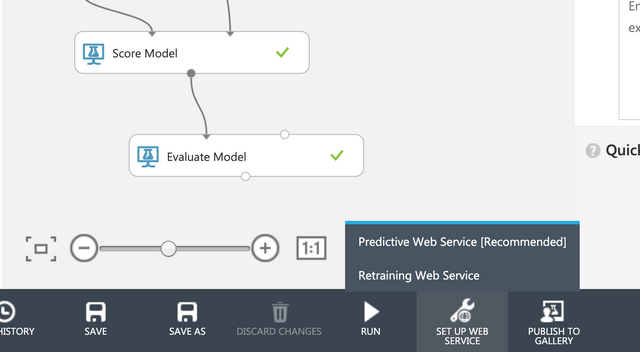
바로 모델을 활용할 수 있는 RESTful 웹사이트가 Azure기반으로 생성된다. 많은 기술들을 사용해야하는데 무척 쉽게 자동으로 생성이 된다.
setup web servervice 리커멘드를 선택한다. 탭이 하나가 더 생긴 것을 볼 수 있다.
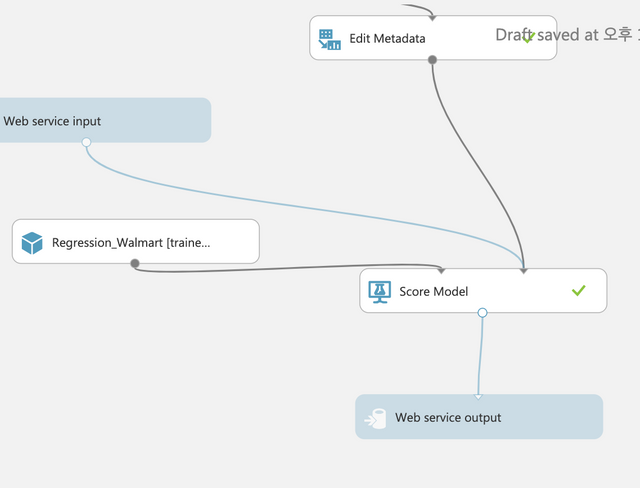
Web service input을 아래쪽으로 끌어다 두고 Score model의 상단 두번째 점과 연결한다.
다시 Run버튼을 클릭하고 실행이 종료되었으면 하단의 Deploy Web Service를 클릭하면 된다. Test버튼을 클릭하면 생성된 모델을 사용할 수 있따.
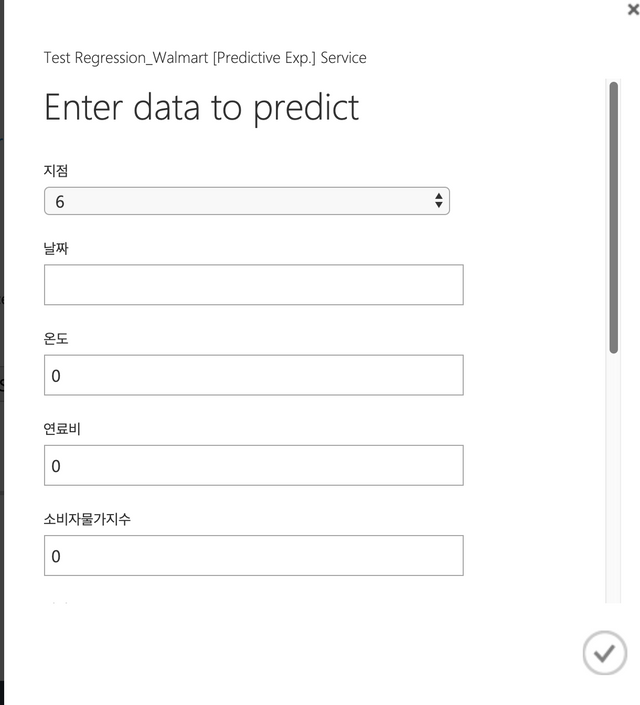
또는 Test preview버튼을 클릭해도 된다.
아래와 같이 샘플 데이터를 바로 로딩해서 테스트 해 볼 수 있다.
윈도우 사용하면서 오피스 2016이면 엑셀로도 다운로드해서 테스트할 수 있다.
판매 금액이 많은 것으로 예측이 되면 직원들을 더 배치할 수 있다. 쿠폰을 주고 판매액을 더 높게 가져갈 수 있다.
마비노기 듀얼에서 Azure ML을 사용하고 있다.
재방문 유도 시스템을 활용하고 있다.
머신러닝이 그렇게 어렵지 않구나 하는 생각
시작점에 도움이 되었으면 좋겠다.